Replica API
Scroll down for code samples, example requests and responses. Select a language for code samples from the tabs above or the mobile navigation menu.
Usage
Authentication
Users need to have an account with API access in Replica Studios in order to use the API.
Subscribed users
Our subscribed users with API access, can create a Personal Access Token via their Account settings in the desktop application. A Personal Access Token client_id and secret can be used with the /v2/auth api endpoint to generate a JWT token, and a refresh token. The JWT token can then be used to make requests to the API.
Legacy Enterprise users
/auth endpoint accepts your username and password as the client_id and secret and returns JWT token
In both cases, once a JWT token is acquired, the token can be used for making further calls by supplying it in Authorization header (Bearer token). The token expires in 1 hour (for more details see Auth).
Text to speech
- For short texts use
/speechendpoint, which immediately returns audio for given text in the form of a link towavfile - For longer texts users have a choice to use a long polling technique, by sending the text to
/submit(same parameters as in/speech) which returns aUUIDof the submitted job. Then results can be polled using/poll/<UUID>. An optionaltimeoutparameter allows to keep the polling request alive for thetimeoutamount of seconds, thus significantly reducing the number of poll requests required.
Quick start
For more advanced users, who worked with a REST API before, we recommend jumping straight to Endpoints documentation.
Below you will find a quick walk-through on how to interact with the API, either manually or programmatically.
Get the access token
First thing you need to do is make a request to Auth endpoint which will provide you the authentication token. This token needs to be attached to all subsequent requests. You will need to provide a pair of credentials (client_id and secret) as params. client_id and secret
Subscribed users will use the details from their Personal Access Tokens, and the /v2/auth endpoint, to fetch a valid JWT token.
Let it speak!
Now, having acquired the access token, we can make requests to any other endpoints. Let's generate some audio from text!
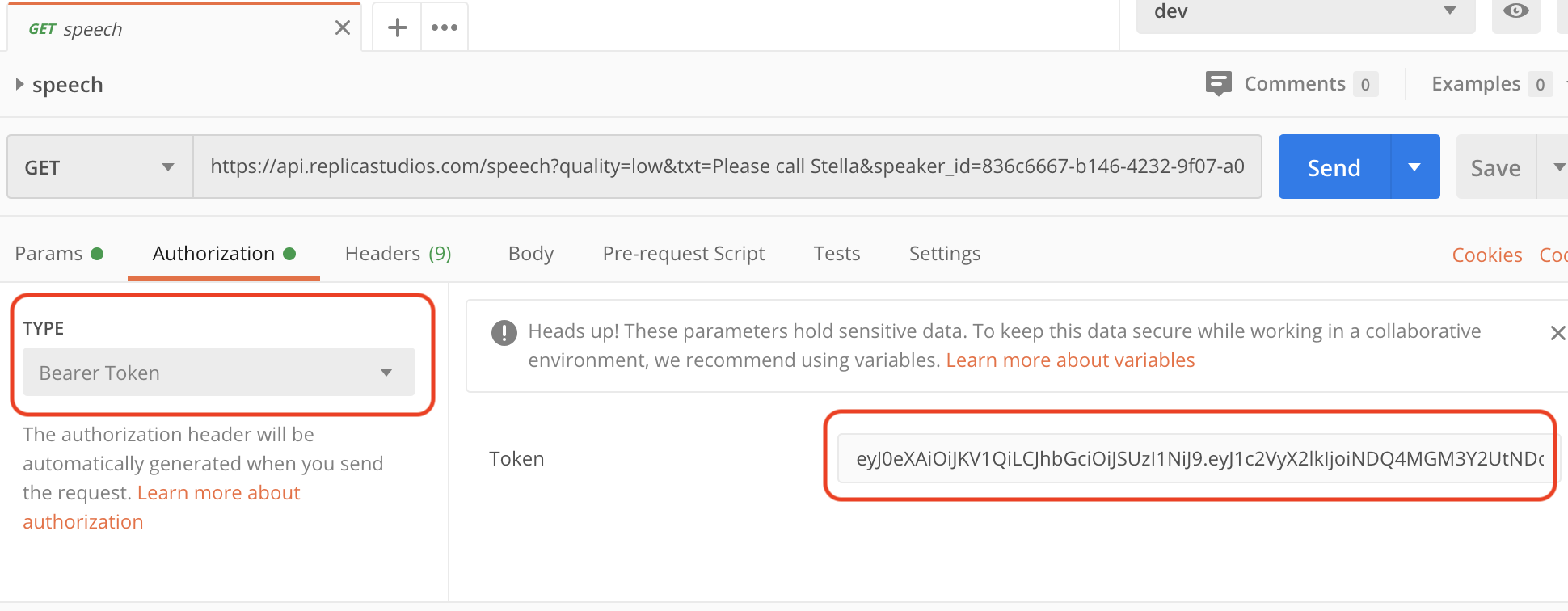
Open the GET speech request tab and go to Authorization section, select TYPE to be Bearer token and paste the token into the input box on the right.
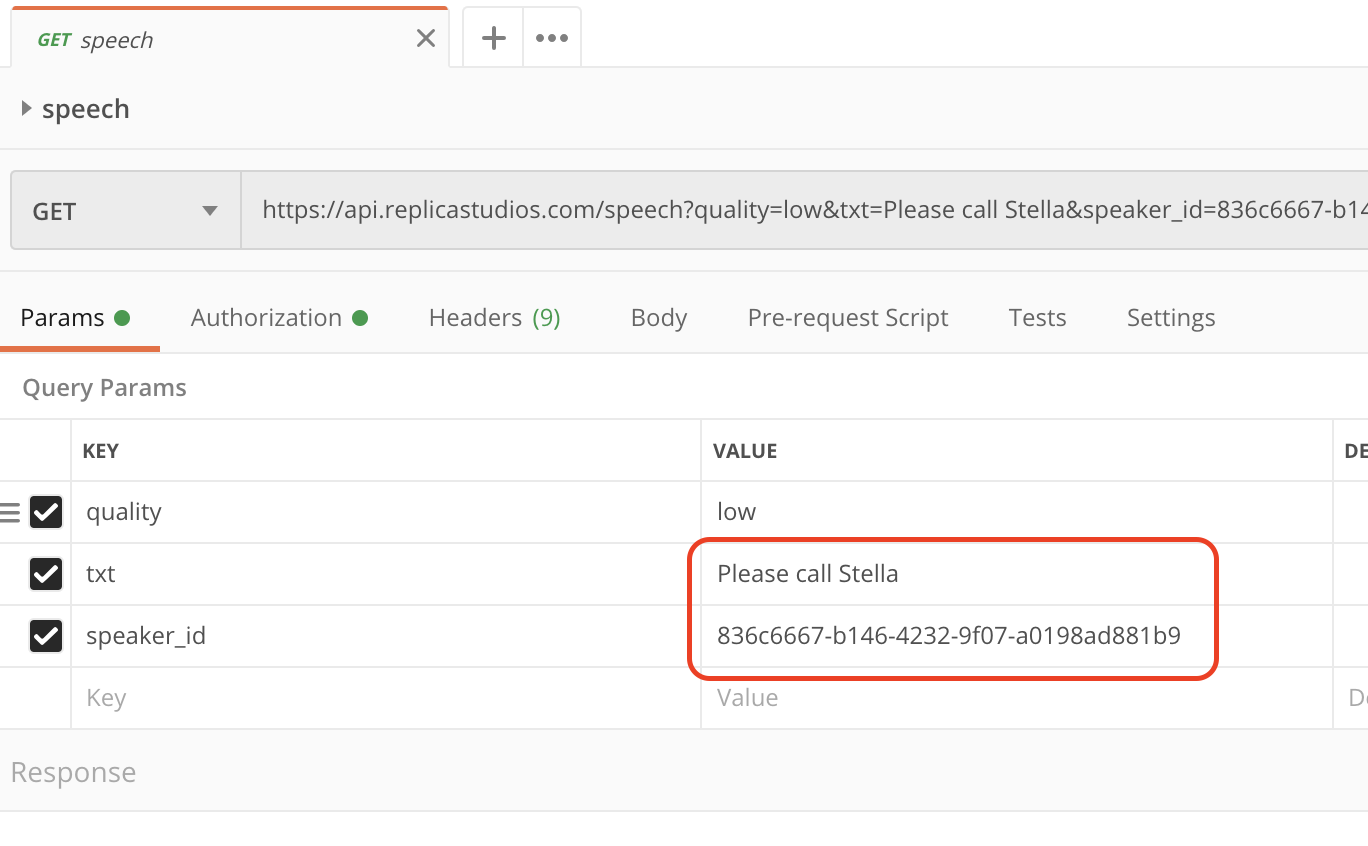
Now go to Params section, where you can find the txt param and speaker_id params which let you set what text should be said by which speaker. A list of available speaker ID's (voices) can be obtained by calling the voice endpoint, for now we can just put c4fe46c4-79c0-403e-9318-ffe7bd4247dd there, which is one of our demo speakers, named Deckard.
You are ready now to hit the Send button, wait a second and you should see the response at the bottom. One of the response fields will be a link to wav file which you can download and play.
Congratulations! You should now hear Deckard reading your script.
If something went wrong, have a look at Troubleshooting section.
Make requests programmatically
The Postman walk-through above is a good introduction to the basic flow of using the API to authenticate and generate audio from text. We also provide a simple Python script, which automates all those steps and can illustrate how to use the API programmatically. Feel free to copy it to your application.
The script is publicly accessible as a Gitlab snippet: https://gitlab.com/snippets/1960032
You can also use the Languages panel on the right side of API Endpoints to get useful snippets of code for other languages.
API endpoints
/v2/auth
Code samples
# You can also use wget
curl -X POST https://api.replicastudios.com/v2/auth \
-H 'Content-Type: application/x-www-form-urlencoded' \
--data-urlencode 'client_id=00000000-0000-0000-0000-000000000001' \
--data-urlencode 'secret=PersonalAccessTokenSecret'
POST https://api.replicastudios.com/v2/auth HTTP/1.1
Host: api.replicastudios.com
Content-Type: application/x-www-form-urlencoded
client_id=00000000-0000-0000-0000-000000000001&secret=PersonalAccessTokenSecret
const inputBody = 'client_id=00000000-0000-0000-0000-000000000001&secret=PersonalAccessTokenSecret';
const headers = {
'Content-Type':'application/x-www-form-urlencoded',
};
fetch('https://api.replicastudios.com/v2/auth',
{
method: 'POST',
body: inputBody,
headers: headers
})
.then(function(res) {
return res.json();
}).then(function(body) {
console.log(body);
});
require 'rest-client'
require 'json'
result = RestClient.post 'https://api.replicastudios.com/v2/auth',
{
:client_id => '00000000-0000-0000-0000-000000000001',
:secret => 'PersonalAccessTokenSecret'
}
p JSON.parse(result)
import requests
headers = {
'Content-Type': 'application/x-www-form-urlencoded'
}
payload = 'client_id=00000000-0000-0000-0000-000000000001&secret=PersonalAccessTokenSecret'
r = requests.post('https://api.replicastudios.com/v2/auth', headers = headers, data = payload)
print(r.json())
POST /v2/auth
V2 Authentication endpoint for subscribed users.
Expects two parameters - client credentials (client_id and secret), as provided by your Personal Access Token, NS encoded as x-www-form-urlencoded in the request body.
Returns a JSON response with JWT token which must be used to make calls to other endpoints. JWT token should be sent as the Authorization: Bearer HTTP header (see examples of calls for other endpoints).
JWT token (jwt.io) is a modern, secure standard for self-contained web access tokens, well suited for stateless REST API's. One of its advantages is that it's not encrypted, but encoded in base64, thus it can be read by both client and server. It includes information about the authenticated client and/or user, permissions and its expiry time. The token is cryptographically signed by our server, hence any tampering with the token will be detected and access will be denied.
We recommend jwt.io site for inspecting the contents of JWT tokens manually. Have a look at our example Python API client to see how to decode and read the token properties programmatically, e.g. check its expiry time.
Note: if your account has used up all credit your token will not authorize you to perform speech generation. This can be checked by decoding the token and verifying if generation permission is present in scopes.
/* sample response */
{
"access_token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1c2VyX2lkIjoiNTg0NmJiMWItYzI2Yy00YTdlLTllYTctMWJmYTc2ZTRkNGNiIiwiZXhwIjoxNTg2MTQ4ODA0LCJpYXQiOjE1ODYxNDcwMDQsInVzZXJfZW1haWwiOiJrYXJvbEByZXBsaWNhc3R1ZGlvcy5jb20iLCJzY29wZXMiOlsiZ2VuZXJhdGUiLCJhZG1pbiJdfQ.YPmwvXC3pU99-t9i9oIA_7wuxE_GjpsJNYn-rFg7KNPUaW8F8QD5laNLdeuZiX9gcF3VvjPVMVX7VTQtrV0nASRa--L5SNBasSVgR59wdwZQpcYOok6Zq0nv0IdTIdiQrkWpKYIsMiVAkJ7EapHO5uSmiUYfueRdGKG2bDaB-qXMOZBZTSZRuoX_1nWStYHwkYuJIz2U1KX167qwCemjEW5O0iTdi1biz7_srw7uAOsFy9YU4QDEKCzLG1OSAYN_APw8_trIqMSJO0Y0S83-CaWorO1zDtOgiAHJW6m_JPaTrg_5xewTWtB5Uji7zjBvhIC9NGcV95CMZqUBgKY1ExJ1ei309Om0QUthxJHIi6FUAYbDSM1UCWXpjAYn6fBQyo4mK-Pfaxqk9GOJVOBOfCrVND_0tyOAGLwe18k0Fl_pLCTIxyPuRQItaeu_S5QPcwqZK_20b1JHVx-siCc5Xv8t6-c9dHE5rWeVdmsgEgAioaTk-ZEnXDizY_vDFn_ZhCgbX-w9_VEQ_LcP9o2lQdGIwkPcVG3HM9WrFChOworQUgUxZiYSQnKnbD2_9BPeQn5hOmN_bPE8lwWoMTJdVJFl9gEV72pA1B-_-NVnTpD9_kENVLYVqilJTCK8UJ_kactbdJweYtVmNIm1R6W8Dmd5t0mYUmOjAmq6MFJpmoo"
}
Parameters
| Name | In | Type | Required | Description |
|---|---|---|---|---|
| Content-Type | header | string | true | |
| client_id | body | string | true | UUID of the client requesting authentication |
| secret | body | string | true | client's secret |
/voice
Code samples
# You can also use wget
curl -X GET https://api.replicastudios.com/voice \
-H 'Authorization: Bearer {token}'
GET https://api.replicastudios.com/voice HTTP/1.1
Host: api.replicastudios.com
Authorization: Bearer {token}
const headers = {
'Authorization':'Bearer {token}'
};
fetch('https://api.replicastudios.com/voice',
{
method: 'GET',
headers: headers
})
.then(function(res) {
return res.json();
}).then(function(body) {
console.log(body);
});
require 'rest-client'
require 'json'
result = RestClient.get 'https://api.replicastudios.com/voice', {
:Authorization => 'Bearer {token}'
}
p JSON.parse(result)
import requests
headers = {
'Authorization': 'Bearer {token}'
}
r = requests.get('https://api.replicastudios.com/voice', headers = headers)
print(r.json())
GET /voice
Endpoint listing all available voices (speakers) for the calling client. Use a speaker_id provided by this api call to select the speaking voice for the TTS /speech endpoint
Parameters
| Name | In | Type | Required | Description |
|---|---|---|---|---|
| Authorization | header | string | true | JWT access token |
/v2/voices
Code samples
# You can also use wget
curl -X GET https://api.replicastudios.com/v2/voices \
-H 'Authorization: Bearer {token}'
GET https://api.replicastudios.com/v2/voices HTTP/1.1
Host: api.replicastudios.com
Authorization: Bearer {token}
const headers = {
'Authorization':'Bearer {token}'
};
fetch('https://api.replicastudios.com/v2/voices',
{
method: 'GET',
headers: headers
})
.then(function(res) {
return res.json();
}).then(function(body) {
console.log(body);
});
require 'rest-client'
require 'json'
result = RestClient.get 'https://api.replicastudios.com/v2/voices', {
:Authorization => 'Bearer {token}'
}
p JSON.parse(result)
import requests
headers = {
'Authorization': 'Bearer {token}'
}
r = requests.get('https://api.replicastudios.com/v2/voices', headers = headers)
print(r.json())
GET /v2/voices
(Alpha) Endpoint listing all available voices and styles (speakers) for the calling client.
The voices object are organized by actor, and the speaker_id can be found either from the default_style object, or from the array of styles nested in the in voice object.
Use a speaker_id provided by this api call to select the speaking voice for the TTS /speech endpoint
Vox-1 is available on a subset of our voices + styles. This can be identified by investigating the tts.vox_1_0 field (true if Vox-1 is available) in the style's capabilities field.
Parameters
| Name | In | Type | Required | Description |
|---|---|---|---|---|
| Authorization | header | string | true | JWT access token |
/speech
Code samples
# You can also use wget
curl -X GET https://api.replicastudios.com/speech?txt=Please call Stella&speaker_id=c4fe46c4-79c0-403e-9318-ffe7bd4247dd&model_chain=classic \
-H 'Authorization: Bearer {token}'
GET https://api.replicastudios.com/speech?txt=Please%20call%20Stella&speaker_id=c4fe46c4-79c0-403e-9318-ffe7bd4247dd&model_chain=classic HTTP/1.1
Host: api.replicastudios.com
Authorization: Bearer {token}
const headers = {
'Authorization':'Bearer {token}'
};
fetch('https://api.replicastudios.com/speech?txt=Please call Stella&speaker_id=c4fe46c4-79c0-403e-9318-ffe7bd4247dd&model_chain=classic',
{
method: 'GET',
headers: headers
})
.then(function(res) {
return res.json();
}).then(function(body) {
console.log(body);
});
require 'rest-client'
require 'json'
result = RestClient.get 'https://api.replicastudios.com/speech', {
:params => {
'txt' => 'Please call Stella',
'speaker_id' => 'c4fe46c4-79c0-403e-9318-ffe7bd4247dd'
'model_chain' => 'classic'
},
:Authorization => 'Bearer {token}'
}
p JSON.parse(result)
import requests
headers = {
'Authorization': 'Bearer {token}'
}
r = requests.get('https://api.replicastudios.com/speech', params={
'txt': 'Please call Stella', 'speaker_id': 'c4fe46c4-79c0-403e-9318-ffe7bd4247dd', 'model_chain': 'classic'
}, headers = headers)
print(r.json())
GET /speech
Text-to-speech (TTS) endpoint.
Supports our new optional model_chain parameter, to start using our Vox-1 voices.
This endpoint is blocking i.e. it will return a response only once it's ready (see /submit for non blocking calls). It usually takes about 1-3 seconds, depending on the length of text and speaker.
The request should contain the text and speaker ID, response will contain a URL to an audio file with the generated speech. By default the format is wav, which is the fastest (no compression cost).
Other optional parameters are extension (audio format), bit_rate and sample_rate to control the output audio properties. Note that not all formats support all possible combinations of bit rate and sample rate, we'll try to return the closest possible.
Note: the returned URL will expire after few days so we do not recommend to store them. They should either be played or downloaded straight away.
/* Sample response */
{
"uuid": "c1aa11f3-3ec6-4830-b2ac-056740ac5b3a",
"generation_time": 0.859611988067627,
"url": "https://dial-s3.s3.amazonaws.com/previews/24000000-0000-0000-0000-000000000000/c1aa11f3-3ec6-4830-b2ac-056740ac5b3a/c1aa11f3-3ec6-4830-b2ac-056740ac5b3a.mp3?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIC53N7WR6G7QL5BA/20200415/us-east-1/s3/aws4_request&X-Amz-Date=20200415T230400Z&X-Amz-Expires=3600&X-Amz-SignedHeaders=host&X-Amz-Signature=d497b7a8f44d4e21c5ca3a522323fa4c0995deca95aec2a21aff54216236bc52",
"duration": 1.2,
"speaker_id": "c4fe46c4-79c0-403e-9318-ffe7bd4247dd",
"txt": "Please call Stella",
"bit_rate": 128,
"sample_rate": 22050,
"extension": "mp3"
}
Parameters
| Name | In | Type | Required | Description |
|---|---|---|---|---|
| Authorization | header | string | true | JWT access token |
| txt | query | string | true | The text to generate |
| speaker_id | query | string | true | Speaker (voice) UUID |
| extension | query | string | false | Output format. Supported: wav (default), mp3, ogg, flac |
| bit_rate | query | int | false | Output bit rate (kbps): 128 (default), 320 |
| sample_rate | query | int | false | Output sample rate (Hz). Supported: 1600, 22050 (default Classic), 44100 (default Vox-1), 48000 |
| model_chain | query | string | false | Inference Model. Supported: classic (default), vox_1_0 |
/speech (long polling)
Code samples
# You can also use wget
curl -X POST https://api.replicastudios.com/speech?speaker_id=c4fe46c4-79c0-403e-9318-ffe7bd4247dd&txt=Please call Stella&model_chain=classic \
-H 'Authorization: Bearer {token}'
POST https://api.replicastudios.com/speech?speaker_id=c4fe46c4-79c0-403e-9318-ffe7bd4247dd&txt=Please%20call%20Stella&model_chain=classic HTTP/1.1
Host: api.replicastudios.com
Authorization: Bearer {token}
const headers = {
'Authorization':'Bearer {token}'
};
fetch('https://api.replicastudios.com/speech?speaker_id=c4fe46c4-79c0-403e-9318-ffe7bd4247dd&txt=Please call Stella&model_chain=classic',
{
method: 'POST',
headers: headers
})
.then(function(res) {
return res.json();
}).then(function(body) {
console.log(body);
});
require 'rest-client'
require 'json'
result = RestClient.post 'https://api.replicastudios.com/speech',
'',
{
:params: {
'speaker_id' => 'c4fe46c4-79c0-403e-9318-ffe7bd4247dd',
'txt' => 'Please call Stella'
'model_chain' => 'classic'
},
:Authorization => 'Bearer {token}'
}
p JSON.parse(result)
import requests
headers = {
'Authorization': 'Bearer {token}'
}
r = requests.post('https://api.replicastudios.com/speech', params={
'speaker_id': 'c4fe46c4-79c0-403e-9318-ffe7bd4247dd', 'txt': 'Please call Stella', 'model_chain': 'classic'
}, headers = headers)
print(r.json())
POST /speech
Non blocking Text-to-speech (TTS) endpoint (note this is a POST request to the same /speech endpoint).
This endpoint is non-blocking i.e. it will return immediately with a JSON response containing UUID of the job.
The TTS results need to be fetched by calling /poll endpoint and providing that UUID.
Same parameters are expected as in non-blocking GET /speech above.
Parameters
| Name | In | Type | Required | Description |
|---|---|---|---|---|
| Authorization | header | string | true | JWT access token |
| speaker_id | query | string | true | speaker (voice) UUID |
| txt | query | string | true | the text to generate |
| model_chain | query | string | false | Inference Model. Supported: classic (default), vox_1_0 |
/speech/{job_uuid} (long polling)
Code samples
# You can also use wget
curl -X GET https://api.replicastudios.com/speech/{job_uuid}?timeout=5 \
-H 'Authorization: Bearer {token}'
GET https://api.replicastudios.com/speech/{job_uuid}?timeout=5 HTTP/1.1
Host: api.replicastudios.com
Authorization: Bearer {token}
const headers = {
'Authorization':'Bearer {token}'
};
fetch('https://api.replicastudios.com/speech/{job_uuid}?timeout=5',
{
method: 'GET',
headers: headers
})
.then(function(res) {
return res.json();
}).then(function(body) {
console.log(body);
});
require 'rest-client'
require 'json'
result = RestClient.get 'https://api.replicastudios.com/speech/{job_uuid}',
{
:params => {
'timeout' => '5',
},
:Authorization => 'Bearer {token}'
}
p JSON.parse(result)
import requests
headers = {
'Authorization': 'Bearer {token}'
}
r = requests.get('https://api.replicastudios.com/speech/{job_uuid}', params={
'timeout': '5'
}, headers = headers)
print(r.json())
GET /speech/{job_uuid}
Endpoint for retrieving results of a job submitted using POST to /speech endpoint.
The job UUID should be supplied as path parameter e.g. /speech/87c0384e-02b0-47d2-a95c-c6b52378000b.
Caller can provide timeout parameter (in seconds) which specifies how long the request should be held before returning, if results are not ready (this is so called "long polling" technique, which reduces the number of calls needed to get the result).
If results are not ready, will return HTTP 404 Not found, meaning that the call needs to be repeated.
As soon as results are ready, will return a response similar to /speech.
Parameters
| Name | In | Type | Required | Description |
|---|---|---|---|---|
| Authorization | header | string | true | JWT token |
| job UUID | path | string | true | UUID of the job e.g. 87c0384e-02b0-47d2-a95c-c6b52378000b |
| timeout | query | integer | false | time (in seconds) to keep request alive if result not ready |
/auth
Code samples
# You can also use wget
curl -X POST https://api.replicastudios.com/auth \
-H 'Content-Type: application/x-www-form-urlencoded' \
--data-urlencode 'client_id=00000000-0000-0000-0000-000000000001' \
--data-urlencode 'secret=mySecretPassword'
POST https://api.replicastudios.com/auth HTTP/1.1
Host: api.replicastudios.com
Content-Type: application/x-www-form-urlencoded
client_id=00000000-0000-0000-0000-000000000001&secret=mySecretPassword
const inputBody = 'client_id=00000000-0000-0000-0000-000000000001&secret=mySecretPassword';
const headers = {
'Content-Type':'application/x-www-form-urlencoded',
};
fetch('https://api.replicastudios.com/auth',
{
method: 'POST',
body: inputBody,
headers: headers
})
.then(function(res) {
return res.json();
}).then(function(body) {
console.log(body);
});
require 'rest-client'
require 'json'
result = RestClient.post 'https://api.replicastudios.com/auth',
{
:client_id => 'my@user.name',
:secret => 'MySecretPassword'
}
p JSON.parse(result)
import requests
headers = {
'Content-Type': 'application/x-www-form-urlencoded'
}
payload = 'client_id=00000000-0000-0000-0000-000000000001&secret=mySecretPassword'
r = requests.post('https://api.replicastudios.com/auth', headers = headers, data = payload)
print(r.json())
POST /auth
Authentication for legacy Enterprise users endpoint.
Expects two parameters - client credentials (client_id and secret) encoded as x-www-form-urlencoded in the request body.
Returns a JSON response with JWT token which must be used to make calls to other endpoints. JWT token should be sent as the Authorization: Bearer HTTP header (see examples of calls for other endpoints).
JWT token (jwt.io) is a modern, secure standard for self-contained web access tokens, well suited for stateless REST API's. One of its advantages is that it's not encrypted, but encoded in base64, thus it can be read by both client and server. It includes information about the authenticated client and/or user, permissions and its expiry time. The token is cryptographically signed by our server, hence any tampering with the token will be detected and access will be denied.
We recommend jwt.io site for inspecting the contents of JWT tokens manually. Have a look at our example Python API client to see how to decode and read the token properties programmatically, e.g. check its expiry time.
Note: if your account has used up all credit your token will not authorize you to perform speech generation. This can be checked by decoding the token and verifying if generation permission is present in scopes.
/* sample response */
{
"access_token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1c2VyX2lkIjoiNTg0NmJiMWItYzI2Yy00YTdlLTllYTctMWJmYTc2ZTRkNGNiIiwiZXhwIjoxNTg2MTQ4ODA0LCJpYXQiOjE1ODYxNDcwMDQsInVzZXJfZW1haWwiOiJrYXJvbEByZXBsaWNhc3R1ZGlvcy5jb20iLCJzY29wZXMiOlsiZ2VuZXJhdGUiLCJhZG1pbiJdfQ.YPmwvXC3pU99-t9i9oIA_7wuxE_GjpsJNYn-rFg7KNPUaW8F8QD5laNLdeuZiX9gcF3VvjPVMVX7VTQtrV0nASRa--L5SNBasSVgR59wdwZQpcYOok6Zq0nv0IdTIdiQrkWpKYIsMiVAkJ7EapHO5uSmiUYfueRdGKG2bDaB-qXMOZBZTSZRuoX_1nWStYHwkYuJIz2U1KX167qwCemjEW5O0iTdi1biz7_srw7uAOsFy9YU4QDEKCzLG1OSAYN_APw8_trIqMSJO0Y0S83-CaWorO1zDtOgiAHJW6m_JPaTrg_5xewTWtB5Uji7zjBvhIC9NGcV95CMZqUBgKY1ExJ1ei309Om0QUthxJHIi6FUAYbDSM1UCWXpjAYn6fBQyo4mK-Pfaxqk9GOJVOBOfCrVND_0tyOAGLwe18k0Fl_pLCTIxyPuRQItaeu_S5QPcwqZK_20b1JHVx-siCc5Xv8t6-c9dHE5rWeVdmsgEgAioaTk-ZEnXDizY_vDFn_ZhCgbX-w9_VEQ_LcP9o2lQdGIwkPcVG3HM9WrFChOworQUgUxZiYSQnKnbD2_9BPeQn5hOmN_bPE8lwWoMTJdVJFl9gEV72pA1B-_-NVnTpD9_kENVLYVqilJTCK8UJ_kactbdJweYtVmNIm1R6W8Dmd5t0mYUmOjAmq6MFJpmoo"
}
Parameters
| Name | In | Type | Required | Description |
|---|---|---|---|---|
| Content-Type | header | string | true | |
| client_id | body | string | true | UUID of the client requesting authentication |
| secret | body | string | true | client's secret |
Controlling pauses, pitch, and other characteristics of your Replica voice
Replica’s AI voices automatically pause with normal punctuation, and generate natural voice with pitch and volume to best synthesize the characteristics and pacing of a real voice.
In some cases, you may want to have additional control over pauses, and other vocal characteristics of the voice. For example, you may to make a voice line sound a bit more dramatic, which you could do by lowering the speaking rate and adding extra pauses to increase the silence between parts of the sentence. Replica supports these controls through the use of Speech Synthesis Markup Language (SSML).
Speech Synthesis Markup Language (SSML)
SSML provides a standard way to markup plain text with tags, which allow more control in generating natural synthetic speech. The following shows an example of how plain text can be marked up with SSML.
Text:
Control the pacing, of your Replica voice. Change its pitch! Or make it louder.
SSML:
<speak>
Control the pacing,<break time="500ms"/> of your Replica voice.
<prosody pitch="2st">Change it's pitch!</prosody>
<prosody volume="loud">Or make it louder.</prosody>
</speak>
Supported SSML tags
Replica supports a subset of the SSML tags defined in the World Wide Web Consortium's SSML specification Version 1.1. The W3 specification may be helpful for additional context and examples.
| Tag | Required | Attributes | Summary |
|---|---|---|---|
| speak | yes | no | Root element for SSML response. |
| break | no | yes | Inserts a pause of given duration. |
| prosody | no | yes | Specifies the pitch, rate, and volume. |
How to use SSML in your response
Using the supported SSML tags build your text for the replica voice to synthesize. Make sure to wrap the text in speak tags, as these are required. Once your SSML input is ready, you can send the request just like any other text in the txt parameter.
For each of the tag attribute the quotation marks need to either be escaped or used in the correct order when using both single and double quotes. The following is a simple example using single quotes for the attributes.
speak
This is the root element of the SSML response.
It is required and needs to encapsulate the whole response. There should be nothing outside of this tag, and inside there should only be text of other Replica supported tags:
Example:
<speak>
Synthesize speech with SSML in your response.
</speak>
Note: The
break
This is an optional tag used to control the pacing of synthesized speech by adding silences or pauses. The Replica voice will automatically synthesize pauses to create natural pacing when no break tags are given.
Attributes
| Attribute | Description | Examples |
|---|---|---|
| time | Specifies the duration of a pause in seconds (s) or milliseconds (ms). Cannot be negative, and can be up to 10 seconds (10s) or 10000 milliseconds (10000ms). Must include the unit ("s" or "ms") with the time value. |
time="2s" time="500ms" |
| strength |
|
strength="weak" |
Example:
<speak>
Use breaks to add pauses to your Replica voice,
<break time="400ms">
and adjust the pacing to fit your story.
</speak>
Note: This tag cannot be added within a word.
prosody
This is an optional element used to modify the volume, rate, and pitch of synthesized speech.
Attributes
| Attribute | Description | Examples |
|---|---|---|
| Volume |
|
volume="soft" volume="+3dB" volume="-0.5dB" |
| Rate |
|
rate="fast" rate="50%" rate="120%" |
| Pitch |
|
pitch="low" pitch="20%" pitch="-3st" |
Example:
<speak>
To make a voice sound scarier, you can:
<prosody rate="slow">Slow the rate of your Replica voice.</prosody>
<prosody pitch="-2st">Decrease it's pitch!</prosody>
<prosody volume="loud">And make it louder.</prosody>
</speak>
NOTE: - Prosody is best applied to a full sentence. - This tag cannot be added within a word. - You can combine multiple prosody attributes within a single tag.
Example:
<prosody volume="loud" pitch="low">
Decrease the pitch and make it louder.
</prosody>
Troubleshooting
General API Troubleshooting
There is a max limit of 2000 characters per request. For longer texts, please split them into multiple requests.
There is a min limit of 2 characters per request.
If you run out of quota, you will not be able to make any more requests. Please contact Replica Studios to purchase more.
Partial success will yield a result with the warning field populated, and the audio will be generated and returned as per a succesful request.
Incorrect request parameters will result in 400 Bad Request response.
Failed speech generation will result in JSON response containing the error code and textual description.
Example:
{
"error_code": 40003,
"error": "Sorry your request failed to generate. Please try again, or consult our FAQ."
}
| error codes | descriptions |
|---|---|
| 20002 | Invalid parameters (e.g. wrong values for any of API params like wrong speaker UUID, invalid model chain or unsupported format.) |
| 40003 | Failed audio generation - this usually means the Machine Learning model has problems generating the particular text it received - usually the reason will be some weird characters, non-English words, or extremely long sentences. |
| 40002 | Generic Machine Learning server error (ie unexpected error) |
SSML Troubleshooting
Incorrect SSML attributes will result in a warning in the response, but will still generate the audio. The warnings will have extra details to let you know which attributes are available for the tag that caused the warning, or what limits the values need to be within.
Make sure that the <speak></speak> tags are present and that there is no text before the first and after the last.
The break tag is used on its own. There is not opening and closing tag for it.
The break tag works best after punctuation to lengthen the pause already generated by the Replica voice.
Make sure that the attribute values for any tag are wrapped in the correct quotes if using a mix of single and double quotes.
When a tag is added between 2 words, the space character between them should be left on either side of the tag, but not removed entirely.
If the warnings do not help, the W3 specification may be helpful with additional examples.
Help and feedback
You can contact us for further assistance or report bugs.
We would love to hear your feedback.